Inventaire
Libre collaborative resource mapper powered by open-knowledge


This repository hosts Inventaire.io source code. Its a collaborative resources mapper project, while yet only focused on exploring books mapping with wikidata and ISBNs
This repository tracks the server-side developments, while the (heavy) client-side can be found here. Client-related technical issues should go in the client repo, while this repo gathers all other technical issues. Non-technical discussions such as feature requests should preferably happen in the roadmap. In doubt, just use your best guess or come ask on the chat :)
Summary
- Installation
- Inventaire stack map
- Concepts map
- Contribute
- API
- Administration
- Day-dreaming on future evolutions
- License
Installation
This is the installation documentation for a developement environment. For production setup, see: inventaire-deploy
Dependencies to install manually:
- git, curl (used in some installation scripts), graphicsmagick (used to resize images), inotify-tools (used in API tests scripts)
- NodeJS (>=6, recommended 12.2), NVM (allows great version update flexibility)
- a CouchDB (>=1.6, recommended 1.7) instance (on port 5984 for default config)
- an ElasticSearch (>=2.4) instance (on port 9200 for default config)
To install those on Ubuntu that could give something like:
sudo add-apt-repository ppa:couchdb/stable -y
sudo apt-get update
sudo apt-get install git curl wget graphicsmagick couchdb inotify-tools
# Install ElasticSearch and its main dependency: Java
# You might want to make sure that no previous version of Java is installed first as it might trigger version issues:
# ElasticSearch requires Java 8/Oracle JDK version 1.8. See https://www.elastic.co/guide/en/elasticsearch/reference/current/_installation.html
# (yes, piping a script to bash is a bad security habit, just as is executing anything on your machine coming from the wild and internet without checking what it does, but we trust this source. For the sake of good practices, you may want to read the script first though ;) )
curl https://raw.githubusercontent.com/inventaire/inventaire-deploy/d8c8bee46c241ceca0ddf3d9c319d84bfb0734d9/install_elasticsearch | bash
# Installing NodeJs and NPM using NVM, the Node Version Manager https://github.com/creationix/nvm
# (see above text on piping a script)
curl https://raw.githubusercontent.com/creationix/nvm/v0.32.1/install.sh | bash
exit(reopen terminal)
# Check that the nvm command can be found
# If you get a 'command not found' error, check NVM documentation https://github.com/creationix/nvm#installation
nvm
nvm install 8Project development environment installation
git clone https://github.com/inventaire/inventaire.git
cd inventaire
npm install
# If you haven't done it previously, set an admin on CouchDB and update ./config/local.js accordingly
curl -XPUT http://localhost:5984/_config/admins/yourcouchdbusername -d '"'yourcouchdbpassword'"'You are all set! You can now start the server (in watch mode so that it reboots on file changes)
npm run watchIf you want to work on the client code, you also need to start Brunch in another terminal
cd client
npm run watchInstallation tips
- To use executable that are used by the project (such as
mocha,couch2elastic4sync), you can either find them in./node_modules/.binor install them globally with npm:npm install -g mocha brunch bower supervisoretc. - If your computer has many CPU cores, you can make Brunch compile even faster by setting an environment variable:
BRUNCH_JOBS=4
Repositories and Branches
server
- master: the stable branch. Unstable work should happen in feature-specific branches and trigger pull requests when ready to be merged in master. See Code Contributor Guidelines.
client
- master: the stable branch. Unstable work should happen in feature-specific branches and trigger pull requests when ready to be merged in master. See Code Contributor Guidelines.
i18n
the repo tracking strings used in the client and emails in all the supported languages. For helping to translate, see translate.inventaire.io
- master: tracking translations fetched from the translation tool and build scripts
- dist: same as master but with pre-built files
deploy
tracking installation scripts and documentation to run inventaire in production
- master: the main implementation targeting Ubuntu 16.04. Additional branches can be started to document installation on other environments
docker
- master: tracking docker installation files for development and testing use
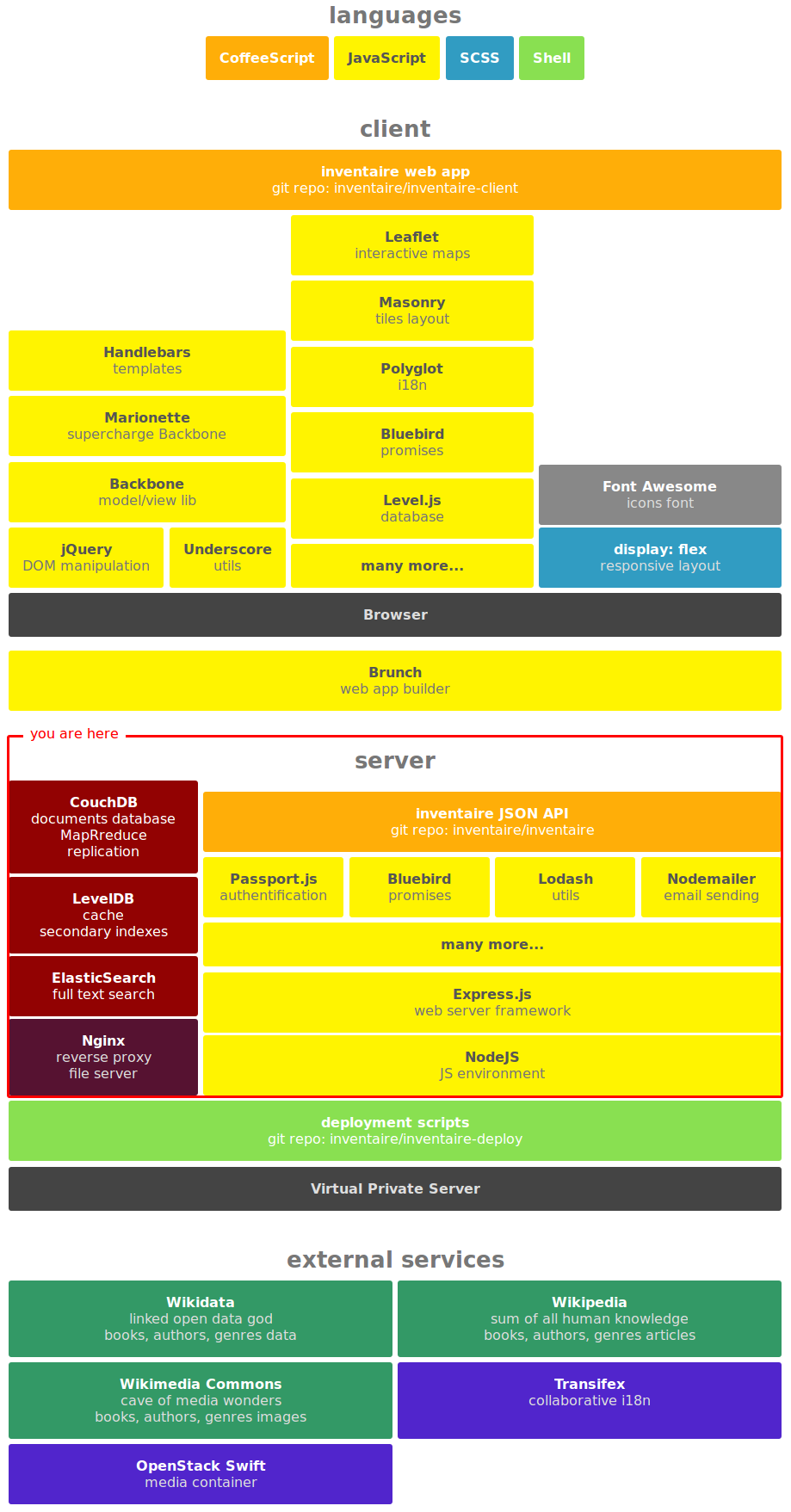
Inventaire stack map
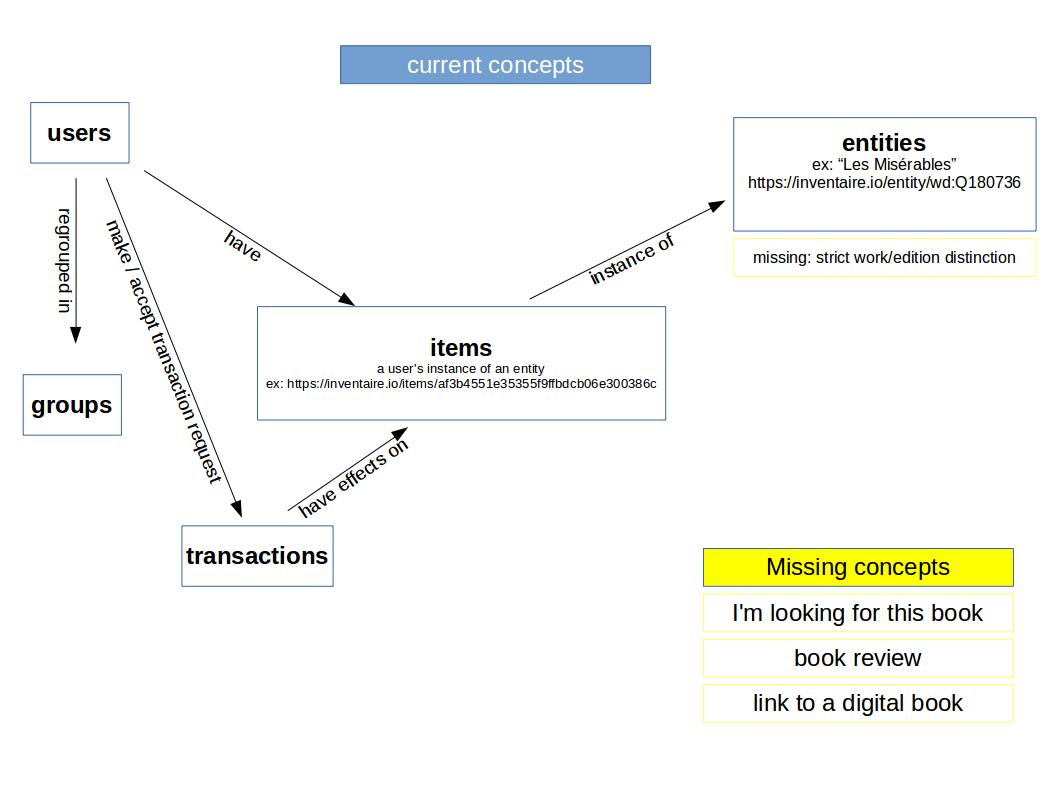
Concepts map
the app has a few core concepts:
- Users
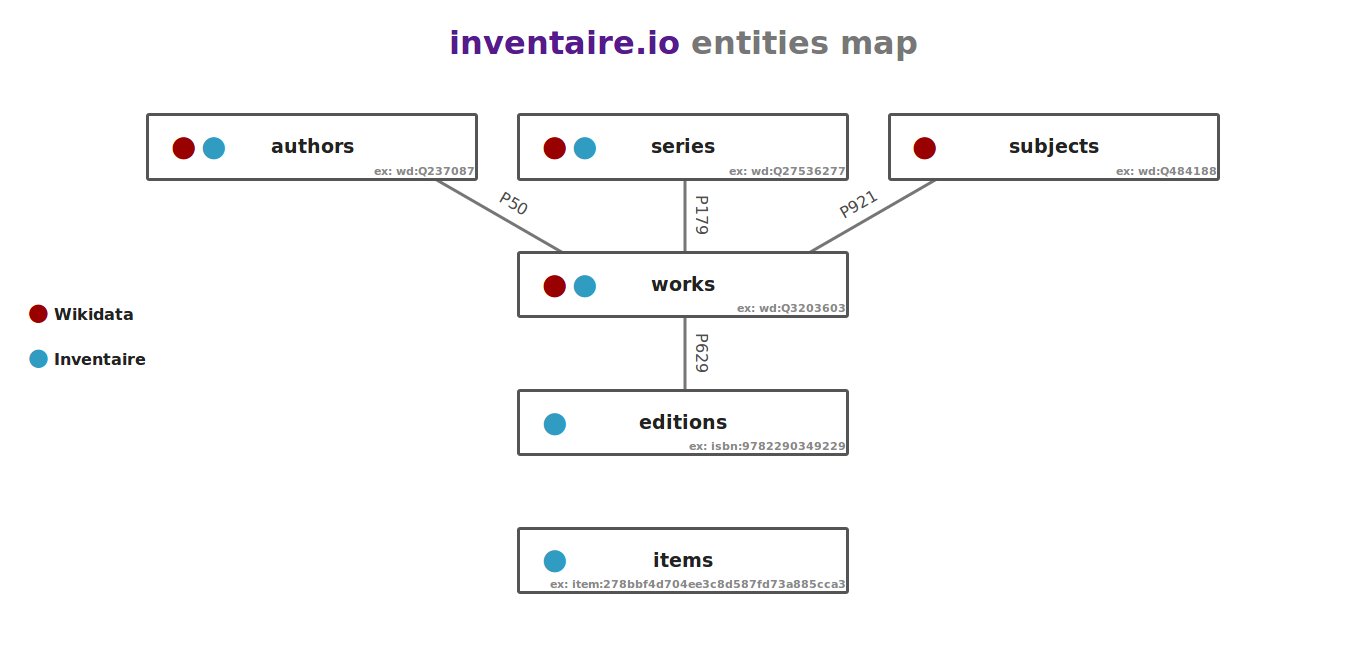
- Entities : which can be authors (ex: wd:Q353), books (ex: wd:Q393018) and books' specific editions (ex: isbn:9782070389162). The term entities comes from wikidata terminology. See the entities map.
- Items : instances of book entities that a user says they have. It can be an instance of a work or a specific edition of a work.
- Transactions : discussion between two users about a specific item with an open transaction mode (giving, lending, selling). Transactions have effects on items: giving and selling an item make it move from the owner to the requester inventory; lending an item shows it as unavailable.
- Groups: groups of users with one or more admins
Contribute
For code-related contributions, see the repo wiki to get started, especially the new contributors section. For a more general introduction to contribution, see How to contribute on wiki.inventaire.io.
Documentation
see docs
API
see wiki: API
Administration
see Administration
Day-dreaming on future evolutions
Inventaire.io is a hub for open-knowledge-based peers inventory data. This prototype uses a centralized database to make the early development easier, while being as easy as possible to 'install' and use: well, it's just a "classic" social network. Meanwhile, this repository is public as there is no reason it should always stay centralized: this is a research work in progress, if you can think of a better/more decentralized way for peers to keep their inventory data and share it with others, you are very welcome to join the effort or experiment on your own with what you can find here. The hard point being sharing data between this centralized website and other inventory implementations. Works on a standard data model and an API would be a priority as soon as meaningful.
Ideas for experimentations:
- port to custom desktop clients using node-webkit or alike
- port to an app for personal cloud platforms: Cozy, NextCloud...
- server-less/P2P inventory sharing using WebRTC DataChannel / WebTorrent / IPFS / Ethereum / OpenBazaar / Scuttlebot / you name it
- any other IndieWeb / Unhosted crazyness? :)
Already experiementing
- the API should allow a first level of decentralization: having personal clients allowing to manage an inventory out of inventaire.io but that could publish on inventaire.io what belongs there, public and semi public items, while keeping private items private. see Labs settings